Flume 是一个分布式、可靠且高可用的服务,用于有效地收集,聚合和移动大量日志数据。它具有基于流数据的简单灵活架构,良好的可靠性机制、故障转移和恢复机制,具有强大的容错性。它支持在系统中定制各类数据发送方,用于收集数据;同时Flume 提供对数据的简单处理,并具有写到各种数据接收方的能力。
Flume 发展历程?
Flume 最初是 Cloudera 开发的日志收集系统,受到了业界的认可与广泛应用,后来逐步演化成支持任何流式数据收集的通用系统。
Flume 目前存在两个版本:Flume OG(Original generation) 和 Flume NG (Next/New generation)。
其中 Flume OG 对应的是 Apache Flume 0.9.x 之前的版本,早期随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.9.4. 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,Cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动,重构后的版本统称为 Flume NG(next generation)。同时此次改动后,Flume 也纳入了 apache 旗下。
Flume NG 在 OG的架构基础上做了调整,去掉了中心化组件 master 以及服务协调组件 Zookeeper,使得架构更加简单和容易部署。Flume NG 和 OG 是完全不兼容的,但沿袭了 OG 中的很多概念,包括Source,Sink等。
Flume 基本思想及特点
Flume 采用了插拔式软件架构,所有组件均是可插拔的,用户可以根据自己的需求定制每个组件。Flume 本质上我理解是一个中间件。
Flume 主要具有以下几个特点:
- 良好的扩展性;Flume 的架构是完全分布式的,没有任何中心化组件,使得其非常容易扩展。
- 高度定制化;采用插拔式架构,各组件插拔式配置,用户可以很容易的根据需求自由定义。
- 良好的可靠性;Flume 内置了事务支持,能保证发送的每条数据能够被下一跳收到而不丢失。
- 可恢复性;依赖于其核心组件channel,选择缓存类型为FileChannel,事件可持久化到本地文件系统中。
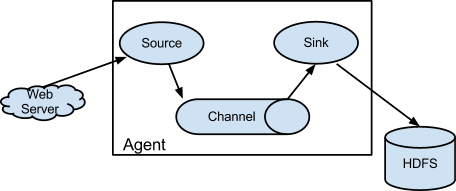
Flume NG 基本架构
Flume 的数据流是通过一系列称为 Agent 的组件构成的,Agent 为最小的独立运行单位。
从上图看出:一个 Agent 可以从客户端或前一个 Agent 接受数据,经过过滤(可选)、路由等操作,传递给下一个或多个 Agent,直到抵达指定的目标系统。用户可根据需求拼接任意多和 Agent 构成一个数据流流水线。
Flume 将数据流水线中传递的数据成为 Event;每个 Event 由头部和字节数组(数据内容)两部分构成,其中,头部由一系列key/value对构成,可用于数据路由;字节数组封装了实际要传递的数据内容,通常是由 avro,thrif,protobuf 等对象序列化而成。
Flume 中 Event 可有专门的客户端程序产生,这些客户端程序将要发送的数据封装成 Event 对象,调用 Flume 提供的 SDK 发送给 Agent。
Flume NG 基本架构之核心组件
Flume Agent 主要由三个组件构成,分别是 Source、channel、Sink。
主要作用和功能如下:
- Source
Flume 数据流中接受 Event 的组件,通常从 Client 程序或上一个 Agent 接受数据,并写入一个或多个 Channel。Flume 提供了多种 Source 实现。
不同类型的 Source:
- 与系统集成的 Source: Syslog, Netcat
- 自动生成事件的 Source: Exec
- 监听文件夹下文件变化:Spooling Directory Source, Taildir Source
- 用于 Agent 和 Agent 之间通信的IPC Source: Avro、Thrift
- Channel
Channel 是一个缓存区,是连接 Source 和 Sink 的组件,它缓存 Source 写入的 Event,直到被 Sink 发送出去。
目前Flume主要提供了一下几种Channel:
- Memory Channel:在内存队列中缓存 Event。该 Channel 具有非常高的性能,但出现故障后,内存中的数据会丢失,另外,内存不足时,可能导致Agent崩溃。
1 |
a1.channels = c1 |
type:类型名称,memory
capacity:存放的Event最大数目,默认10000
transactionCapacity:每次事务中,从Source服务的数据,或写 入sink的数据(条数)
byteCapacityBufferPercentage:Header中数据的比例,默认20
byteCapacity:存储的最大数据量(byte)
- File Channel:在磁盘文件中缓存 Event。该 Channel 弥补了 Memory Channel 的不足,但性能吞吐率有所下降
1 |
a1.channels = c1 |
type:类型名称,file
checkpointDir:Checkpoint文件存放位置
dataDirs:数据目录,分隔符分割
- JDBC Channel:支持 JDBC 驱动,进而可将 Event 写入数据库中。该 Channel 适用于对故障恢复要求较高的场景
- KafKa Channel:在 KafKa 中缓存 Event。KafKa 提供了高容错性,允许可靠地缓存更多的数据,这为 Sink 重复读取 Channel 中的数据提供了可能
- Sink
Sink 负责从 Channel 读取数据 ,并发送给下一个Agent的Source或者文件存储系统。
目前 Flume 主要提供了一下几种 Sink 实现:
- Hdfs Sink:最常用的 Sink,负责将 Channel 中的数据写入HDFS
1 |
a1.channels = c1 |
type:类型名称,hdfs
hdfs.path:HDFS目录
hdfs.filePrefix:Flume写入HDFS的文件前缀
hdfs.rollInterval:文件滚动时间间隔(单位:秒)
hdfs.rollSize:文件滚动大小(单位:byte)
hdfs.rollCount:hdfs.rollCount
- HBase Sink:可将 Channel 中的数据写入 HBase,支持同步或者异步两种方式
1 |
a1.sinks = k1 |
type:类型名称,hbase
table:Hbase Table名称
Column family:Hbase Table中column family名称
zookeeperQuorum:Hbase中zookeeper地址,hbase-site.xml中的 hbase.zookeeper.quorum中参数值
znodeParent:hbase-site.xml中的zookeeper.znode.parent中参数值
- Avro/Thrift Sink:内置了 Avro/Thrift 客户端 ,可将 Event 数据通过 Avro/Thrift 发送给指定的 Avro/Thrift 客户端
- KafKa Sink:可将 Channel 中的数据写入 Kafka
- Hive Sink :可将 Channel 中的数据写入 Hive