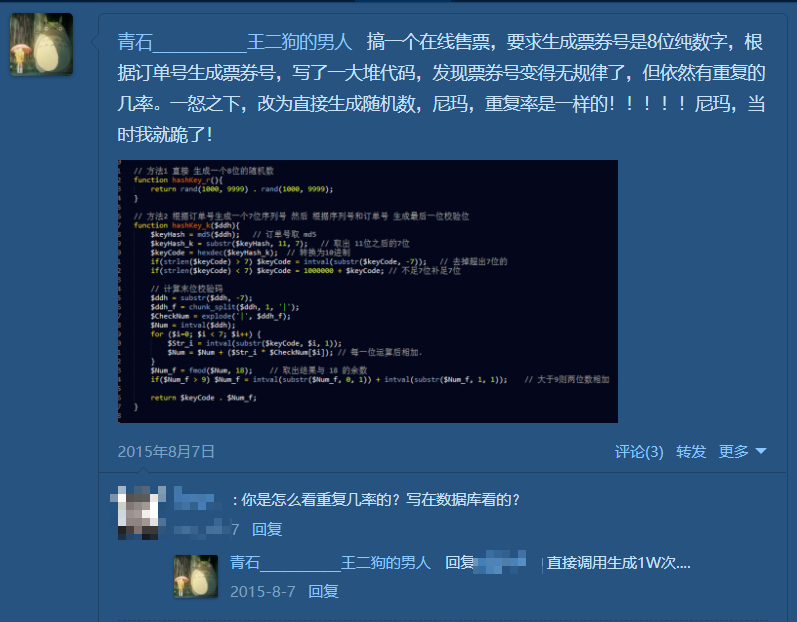
有没有什么生成随机不重复的唯一 ID 且足够短的好办法?
資深大佬 : kaiki 11
B 站的 bv 号那种就感觉可以,但是太长,我想生成只有几位的数字+大小写字母组合的随机字符表作为 ID,但是怕万一随机出以前出过的 ID
大佬有話說 (67)
我当初设计过一款唯一访问 key,思路你参考下:
key 的参与构造字符,我用的是数字 10,大写字母 26,小写字母 26,虽然还可以用一部分单位符号但我没选,这样我的 key 只要 8 位字符就是 62 的 8 次方,就远远超过了 imei 的 15 纯数字位组合,而且还留下了巨大的空间,至于去重,我是每次随机生成完都检查一下是否已存在实现的,如果你对查重有性能要求的话需要重点改造下这个地方
15 年,公司接了一个电商买公交乘车码的东西,乘客手机购买后生成数字序列号给司机验证后可乘车。
由于需要手输,所以数字要短,当时做过一些研究,主可以参考一下结论(一定量情况下,直接随机数和瞎搞胡搞的看起来随机的没差):

然后附上我前段时间搞得一个离线 CDK,里面又一些思路主可以参考:
顺序生成,但是通过在二进制上一定的变换,可以得到看似随机的结果,但和原值一一对应,不重复。
https://www.qs5.org/Post/680.html
( 15 年时我还很菜,别喷,虽然我现在依然菜,但谁喷我 ,我就画圈圈骂谁。)
都是直接对 id 进行可逆加密的办法。
另外也可以考虑直接用 aes 等方式加密。
而且连续两个数之间可能看不出规律(不知道处理方式的情况下)。
代码很简单:
for(int i = len – 1; isEncrypt && i > 0; code = garble(code)) {
–i;
}
private static String garble(String str) {
int len = str.length();
String first = len > 2 ? str.substring(0, 1) : “”;
String high = len > 3 ? str.substring(1, len – 2) : “”;
String low = String.valueOf(set.get(str.substring(len – 2, len)));
return high + low + first;
}
“`js
import { customAlphabet } from ‘nanoid’
const nanoid = customAlphabet(‘1234567890abcdef’, 10)
model.id = nanoid() //=> “4f90d13a42”
“`
再说你真设计一个系统,你当然要考虑设计安全性,像我说的你如果完全没有碰撞处理方案,那随便一个人稍微有点恶意,传了经过设计的特殊字串,就能让你的程序抛出异常,这是完全有可能发生的情况而不是什么极小概率事件,显然设计过系统的都没法接受。也不知道现在杠精这么多都在杠什么,如果你们写程序的时候就真不加碰撞处理的代码,那我们也不用讨论什么了,道不同不相为谋,没必要